摘要
文章做了一个大规模的NMT系统调优实验,寻找最好的模型结构参数,各种trick.
实验结果
1. Embedding Dimensionality(词向量维度)
| Dim | newstest2013 | Params |
|---|---|---|
| 128 | 21.50 ± 0.16 (21.66) | 36.13M |
| 256 | 21.73 ± 0.09 (21.85) | 46.20M |
| 512 | 21.78 ± 0.05 (21.83) | 66.32M |
| 1024 | 21.36 ± 0.27 (21.67) | 106.58M |
| 2048 | 21.86 ± 0.17 (22.08) | 187.09M |
词向量维度不是越大越好,128维的词响亮收敛速度两倍快.
2. RNN Cell Variant(RNN类型)
| Cell | newstest2013 | Params |
|---|---|---|
| LSTM | 22.22 ± 0.08 (22.33) | 68.95M |
| GRU | 21.78 ± 0.05 (21.83) | 66.32M |
| Vanilla-Dec | 15.38 ± 0.28 (15.73) | 63.18M |
LSTM cells consistently outperformed GRU cells
实验测出来LSTM比GRU好,而且速度也没差多少.所以用LSTM应该不亏.
3. Encoder and Decoder Depth(模型深度)
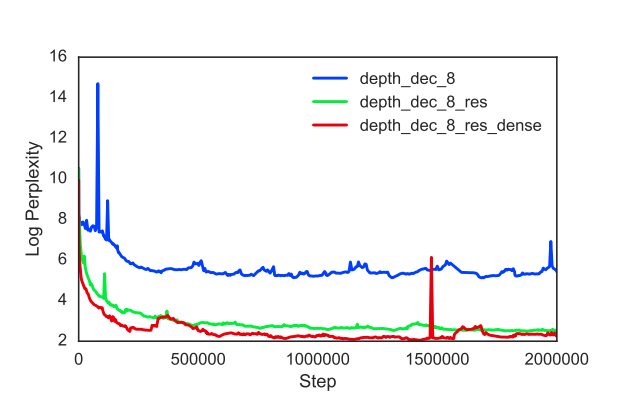
模型中加入了residual connections(残差连接),
$$x^{(l+1)}=h_t^{(l)}(x_t^{(l)}, h_{t-1}^{(l)})+x_t^{(l)}$$
其中\(h_t^{(l)}(x_t^{(l)}, h_{t-1}^{(l)}\)表示\(l\)层在第\(t\)个step的输出.加入了residual后效果得到了明显的提升.
| Depth | newstest2013 | Params |
|---|---|---|
| Enc-2 | 21.78 ± 0.05 (21.83) | 66.32M |
| Enc-4 | 21.85 ± 0.32 (22.23) | 69.47M |
| Enc-8 | 21.32 ± 0.14 (21.51) | 75.77M |
| Enc-8-Res | 19.23 ± 1.96 (21.97) | 75.77M |
| Enc-8-ResD | 17.30 ± 2.64 (21.03) | 75.77M |
| Dec-1 | 21.76 ± 0.12 (21.93) | 64.75M |
| Dec-2 | 21.78 ± 0.05 (21.83) | 66.32M |
| Dec-4 | 22.37 ± 0.10 (22.51) | 69.47M |
| Dec-4-Res | 17.48 ± 0.25 (17.82) | 68.69M |
| Dec-4-ResD | 21.10 ± 0.24 (21.43) | 68.69M |
| Dec-8 | 01.42 ± 0.23 (1.66) | 75.77M |
| Dec-8-Res | 16.99 ± 0.42 (17.47) | 75.77M |
| Dec-8-ResD | 20.97 ± 0.34 (21.42) | 75.77M |
We expected deep models to perform better across the board
实验中4层的时候结构更好,还是根据数据来调整.但是文章认为,更深的模型表现会更好,只是还没有找到更好的深度序列模型优化技术.
4. Unidirectional vs. Bidirectional Encoder(单双向编码器)
| Cell | newstest2013 | Params |
|---|---|---|
| Bidi-2 | 21.78 ± 0.05 (21.83) | 66.32M |
| Uni-1 | 20.54 ± 0.16 (20.73) | 63.44M |
| Uni-1R | 21.16 ± 0.35 (21.64) | 63.44M |
| Uni-2 | 20.98 ± 0.10 (21.07) | 65.01M |
| Uni-2R | 21.76 ± 0.21 (21.93) | 65.01M |
| Uni-4 | 21.47 ± 0.22 (21.70) | 68.16M |
| Uni-4R | 21.32 ± 0.42 (21.89) | 68.16M |
双向的效果更好,但差距不是太大.
5. Attention Mechanism(注意力机制)
有两种的注意机得分的计算方法,加法变种和乘法变种,其中乘法变种的计算更快.\(W_1 j_j\)和\(W_2 s_i\)的维度成为注意力维度,一般取128到1024.
$$sorce(h_j,s_i)=< v,\;tanh(W_1 j_j+W_2 s_i) >$$ $$sorce(h_j,s_i)=< W_1 h_j,\;W_2 S_i >$$
| Attention | newstest2013 | Params |
|---|---|---|
| Mul-128 | 22.03 ± 0.08 (22.14) | 65.73M |
| Mul-256 | 22.33 ± 0.28 (22.64) | 65.93M |
| Mul-512 | 21.78 ± 0.05 (21.83) | 66.32M |
| Mul-1024 | 18.22 ± 0.03 (18.26) | 67.11M |
| Add-128 | 22.23 ± 0.11 (22.38) | 65.73M |
| Add-256 | 22.33 ± 0.04 (22.39) | 65.93M |
| Add-512 | 22.47 ± 0.27 (22.79) | 66.33M |
| Add-1028 | 22.10 ± 0.18 (22.36) | 67.11M |
| None-State | 9.98 ± 0.28 (10.25) | 64.23M |
| None-Input | 11.57 ± 0.30 (11.85) | 64.49M |
可以看出,加了attention表现更好,而且加法变种的效果更好.
6. Beam Search Strategies
| Beam | newstest2013 | Params |
|---|---|---|
| B1 | 20.66 ± 0.31 (21.08) | 66.32M |
| B3 | 21.55 ± 0.26 (21.94) | 66.32M |
| B5 | 21.60 ± 0.28 (22.03) | 66.32M |
| B10 | 21.57 ± 0.26 (21.91) | 66.32M |
| B25 | 21.47 ± 0.30 (21.77) | 66.32M |
| B100 | 21.10 ± 0.31 (21.39) | 66.32M |
| B10-LP-0.5 | 21.71 ± 0.25 (22.04) | 66.32M |
| B10-LP-1.0 | 21.80 ± 0.25 (22.16) | 66.32M |
LP为长度惩罚,一般设置beam的宽度为10即可.
7. Final System Comparison(最终的模型比较)
模型参数如下
| Hyperparameter | Value |
|---|---|
| embedding dim | 512 |
| rnn cell variant | LSTMCell |
| encoder depth | 4 |
| decoder depth | 4 |
| attention dim | 512 |
| attention type | Bahdanau |
| encoder | bidirectional |
| beam size | 10 |
| length penalty | 1.0 |
各个模型的对比
| Model | newstest14 | newstest15 |
|---|---|---|
| Ours (experimental) | 22.03 | 24.75 |
| Ours (combined) | 22.19 | 25.23 |
| OpenNMT | 19.34 | - |
| Luong | 20.9 | - |
| BPE-Char | 21.5 | 23.9 |
| BPE | - | 20.5 |
| RNNSearch-LV | 19.4 | - |
| RNNSearch | - | 16.5 |
| Deep-Att* | 20.6 | - |
| GNMT* | 24.61 | - |
| Deep-Conv* | - | 24.3 |
链接
论文 Massive Exploration of Neural Machine Translation
数据集 WMT14
注释
所有数据,图表均来源于论文.