摘要
深度神经网络在不同的任务上都表现得很强,但是他却不能被用于将一个序列映射成另外一个序列.在这篇文章,作者们提出了一种端到端的方法来从一个序列学习另外一个序列.方法是:(Encode)用多层的LSTM来将一个输入序列转化为一个固定长度的向量,(Decode)然后再把这个向量丢给另外的LSTM作为输入,输出一个新的序列.
文章基于英语译法语的翻译任务来做实验,结果挺好的.还说了一个trick,将encode输入的句子的单词翻转效果会更好一点,就是"今天 天气 真好",变成"真好 天气 今天",效果会更好.
模型介绍
与上一篇seq2seq的结构不同,那一个的结构中把encoder编码出来的c传给了decoder的每一个时刻,这篇文章中,只把c传给了第一个时刻,作为decoder的初始化hidden state.
模型结构
直接上图
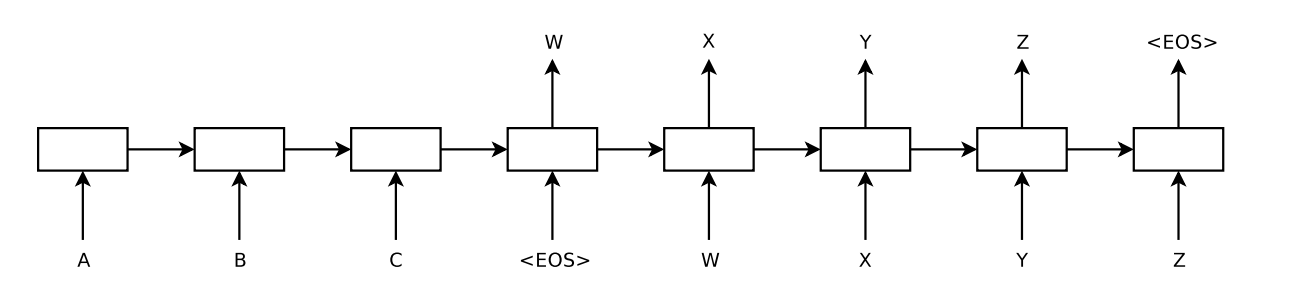
图中,给定序列"ABC",生成一个序列"WXYZ < EOS >",其中< EOS >为结束符号,没有实际意义,用于标记句子结束.
计算过程
给定序列\(x_1,…,x_T\),通过lstm计算得到最后的hidden state \(v\)
$$v=lstm(x_1,…,x_T)$$
将\(v\)作为decoder的初始状态init_state,可以计算概率\(y_1,…, y_T\)
$$p(y_1,…,y_{T’}|x_1,…,x_T)=\prod_{t=1}^{T’}p(y_t|v,y_1,…,y_{t-1})$$
LSTM可以用来估计条件概率\(p(y_1,…,y_{T’}|x_1,…,x_T)\),其中\(x_1,…,x_T\)是输入序列,\(y_1,…, y_{T’}\)是对应的正确的输出序列.
那么对于\(p(y_t|v,y_1,…,y_{t-1})\),所对应的分布可以表示为在词典中所有的词做softmax后得到的值.
目标函数
实验的目的是在大量的句子对上训练一个深度LSTM,目标函数定义为
$$1/|D| \sum_{(T,S)\in D}log p(T|S)$$
D是训练集合中所有的句子,当训练完后,可以通过LSTM,在给定句子S时得到句子\(\hat T\):
$$\hat T=argmax_T p(T|S)$$
在这个解码过程中,可以用beam search 来使得得到的结果更好.
链接
论文 Sequence to Sequence Learning with Neural Networks
注释
所有数据,图表均来源于论文.