摘要
Google推出了一个NMT系统,叫GNMT,文章讲述了这个系统的详情.
模型结构
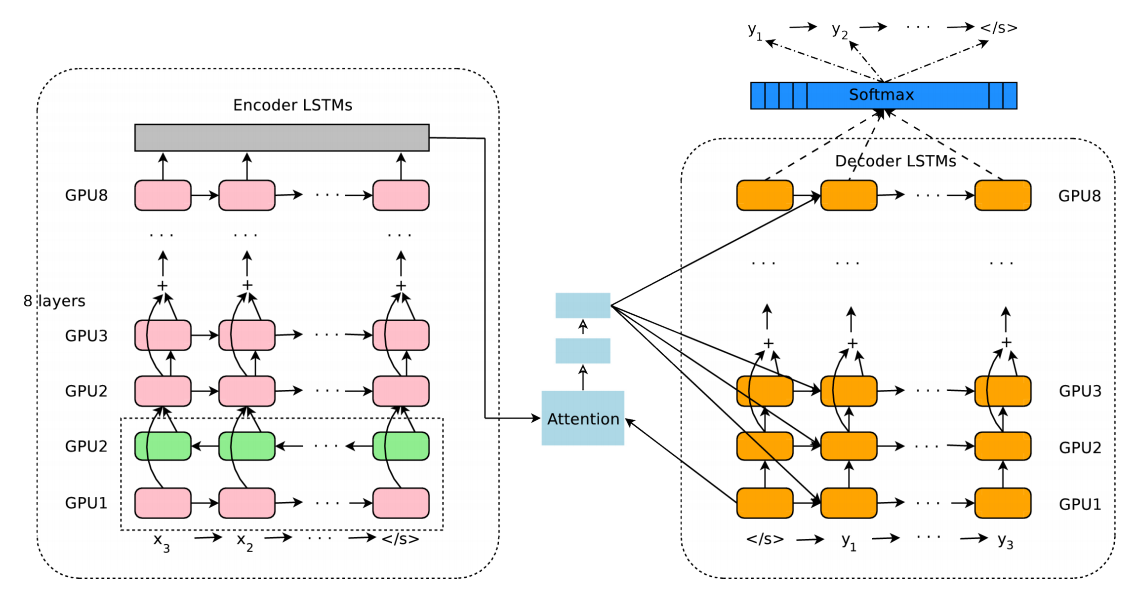
模型包括三个部分:encoder network, decoder network, attention network. encoder将一个句子转换为一组向量,每一个symbol转化为一个向量,decoder根据这组向量在每个time生成一个symbol,直到生成结束符号EOS.在decoder解码时候,decoder通过attention模块与ecoder进行连接,通过这个模块来决定关注源句子的哪些地方来生成句子.
其中,attention模块的计算方式为:
$$s_t=AttentionFunction(y_{y-1},x_t)$$ $$p_t=exp(s_t)/\sum_{t=1}^M exp(s_t)$$ $$a_i=\sum_{t=1}^M p_tx_t$$
与之前的文章讲的不一样,这里的\(AttentionFunction\)用的是decoder的output和encoder的output来计算attention,而不是用decoder的hidder state.
1 Residual Connections(残差连接)
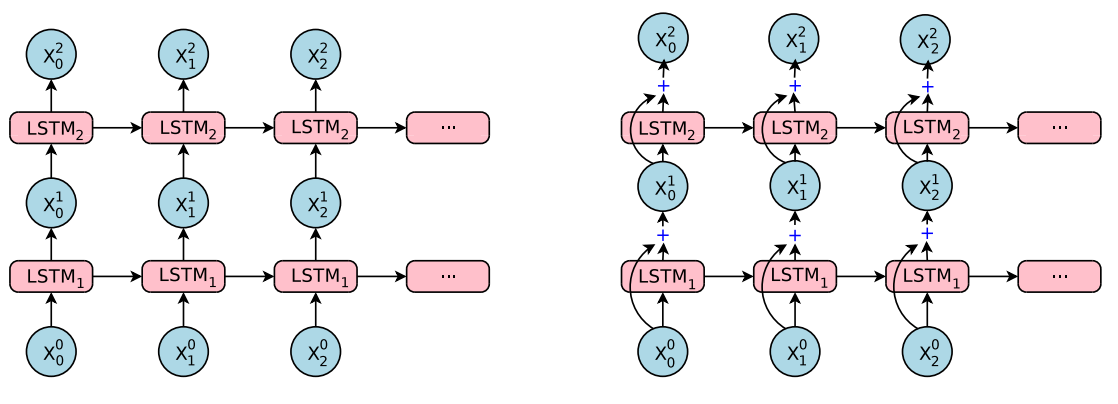
左边是简单叠起来的LSTM,右边是加了Residual connections的,也就是在每一层输出的时候,把输出加上这一层的输入.
也就是原来的计算公式是
$$c_t^i,m_t^i=LSTM_i(c_{t-1}^i,m_{t-1}^i,x_t^{i-1};W^i)$$ $$x_t^i=m_t^i$$ $$c_t^{i+1},m_t^{i+1}=LSTM_{i+1}(c_{t-1}^{i+1},m_{t-1}^{i+1},x_t^{i-1};W^{i+1})$$
加入了residual connections之后变为
$$c_t^i,m_t^i=LSTM_i(c_{t-1}^i,m_{t-1}^i,x_t^{i-1};W^i)$$ $$x_t^i=m_t^i+x_t^{i-1}$$ $$c_t^{i+1},m_t^{i+1}=LSTM_{i+1}(c_{t-1}^{i+1},m_{t-1}^{i+1},x_t^{i-1};W^{i+1})$$
也就是\(x_t^i=m_t^i+x_t^{i-1}\)加上那个了这一层的输出.从图的右边的模型可以看出把下面的加上去了.
2 Bi-directional Encoder for First Layer
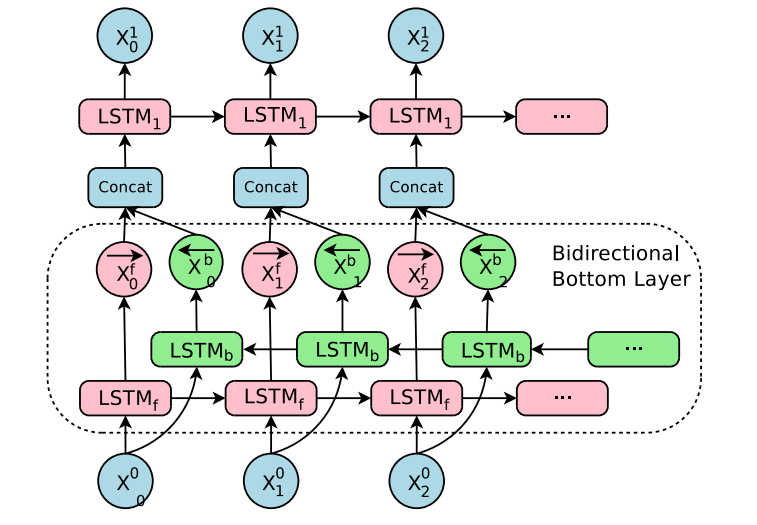
在encoder的第一层用了双向的RNN
至于为什么只在地一层用双向,而不是每一层用,主要是为了可以优化模型的并行计算.
3 Model Parallelism(模型并行)
文章说了用了两个并行方式来处理这个这么复发,模型并行和数据并行.没计算资源忽略
4 Segmentation Approaches(分词方法)
在解决out-of-vocabulary(OOV,未登录词)的方面上,主要有两个方法
One approach is to simply copy rare words from source to target , either based on the attention model, using an external alignment model, or even using a more complicated special purpose pointing network. Another broad category of approaches is to use sub-word units, e.g., chararacters, mixed word/characters, or more intelligent sub-words.
一种是对于未登录词(大多数是名字数字之类的)用简单的复制方法,用一个对其的模型来出来,直接翻译对其.另外一种是用子词(sub-word units)来做,而文章说GNMT就是用第二种来做的.
• Word: Jet makers feud over seat width with big orders at stake
• wordpieces: _J et _makers _fe ud _over _seat _width _with _big _orders _at _stake
其中Jet feud别切开了._为一个标记,代表一个词的开头.
不过可以用BPE来切分子词(与论文的方法有些差别)
5 Training Criteria(训练标准)
给定一个包含N个句子对的平行语料\(D\equiv\lbrace X^{(i)},Y^{*(i)}\rbrace _{i=1}^N\)标准的极大似然估计的训练目的是给定所有的输入,能够正确的输出对应结果的log概率值的总和最大,即
$$O_{ML}(\theta)=\sum_{i=1}^Nlog P_\theta(Y^{*(i)}|X^{i}).$$
因为一些问题(不是很懂),加入了这个
Further, this objective does not explicitly encourage a ranking among incorrect output sequences – where outputs with higher BLEU scores should still obtain higher probabilities under the model – since incorrect outputs are never observed during training.
$$O_{ML}(\theta)=\sum_{i=1}^Nlog P_\theta(Y^{*(i)}|X^{i})r(Y,Y^{*(i)})$$
其中\(r(Y, Y^{*(i)})\)就是GLEU值的计算部分,GLUE的计算方法为取输出与目标句子的n-grams,然后计算交集的个数占两个句子的比例,最后取最小的一个.
为了训练的稳定,将两个式子合起来一起训练
$$O_{Mixed}(\theta)=a*O_{ML}\theta+O_{RL}\theta$$
文中的\(a\)设为0.25
6 可量化的模型和量化推理过程
(略)
7 解码器
针对beam search,提出了两种优化方法,\(s(Y,X)\)是目标函数.
$$s(Y,X)=log(P(Y|X))/lp(Y)+cp(X;Y)$$
length normalization, 因为每个词的log概率值都是负数,因此句子越长,值越小,所以使得更容易产生短句,这不合理.
$$lp(Y)=\frac{(5+|Y|)^a}{(5+1)^a}$$
当句子变长的时候,lp变大,因为\(log(P(Y|X))\)是负数,因此,\(s(Y,X)\)是变大的.这样就可以使得长度不被抑制.防止漏掉一些翻译
$$cp(X;Y)=\beta*\sum_{i=1}^{|X|}log(min(\sum_{j=1}^{|Y|}p_{i,j},1.0))$$
\(p_{i,j}\)是输出的句子的第j个词对于源句子第i个词的注意力概率,假如第k个词漏翻了,那么\(\sum_{j=1}^{|Y|}p_{k,j}\)就会变小,那么\(log(min(\sum_{j=1}^{|Y|}p_{k,j},1.0))\)将会小于0,因此就会导致s(Y,X)降低.所以训练的时候,从而抑制漏翻.
结果如下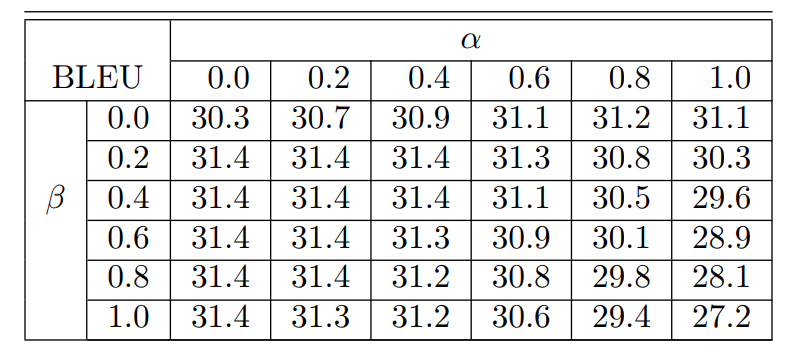
用了这两个优化方法之后,有相应的提高
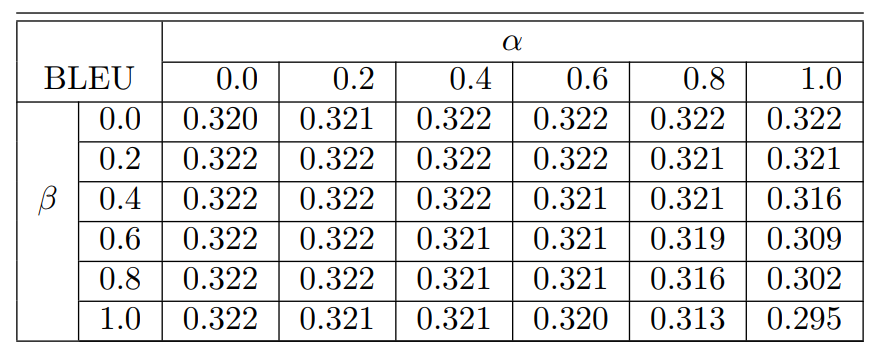
这个图是先同ML训练然后再用RL训练的图和上图的对比,又有一点提高.
链接
论文 Google’s Neural Machine Translation System: Bridging the Gap
注释
所有数据,图表均来源于论文.