摘要
文章考虑了把主题信息结合到seq2seq框架中来使得chatbot生成带有信息和有趣的回复,在文章最后提出了一个主题感知的seq2seq模型.模型利用主题来模拟让人类说话有趣有内涵的先前知识和通过注意力机制联合主题信息来使得生成概率产生偏差.其中主题信息通过预先好的LDA模型来产生.
Topic aware Seq2Seq model
假设有数据集\(D=\lbrace (K_i,X_i,Y_i)\rbrace _{i=1}^N\),其中\(X_i\)是问题,\(Y_i\)是回复,\(K_i\)是\(X_i\)对应的主题的主题词.给定问题\(X\)和主题词\(K\),模型生成\(X\)相应的回答.
模型的学习需要解决两个问题,1)怎样获得主题词;2)怎么学习模型
Topic word acquisition
通过从一个训练好的Twitter LDA模型中获取主题词,使用collapsed Gibbs sampling 算法来估计LDA模型的参数,然后使用训练好的模型为问题\(X\)选择一个主题\(z\),选择\(z\)主题下的前100个词,除去一些常见词比如"你","谢谢"之类的词.那么就吧这些词\(K\)作为\(X\)的主题词.
在模型(TA-Seq2seq)中,需要将每个主题词表示成一个向量才能进行计算,文章的计算方法是计算每个主题词在主题中的分布(词出现在每个主题的概率):
$$p(z|w)\propto {\frac {C_{wz}}{\sum_{z’} C_{wz}}}$$
其中\(C_{wz}\)是词\(w\)在主题\(z\)中出现的次数.在实验中,Twitter LDA模型是使用新浪微薄的数据训练哦.
TA-Seq2Seq
下图展示了Topic aware Seq2Seq model模型的结构: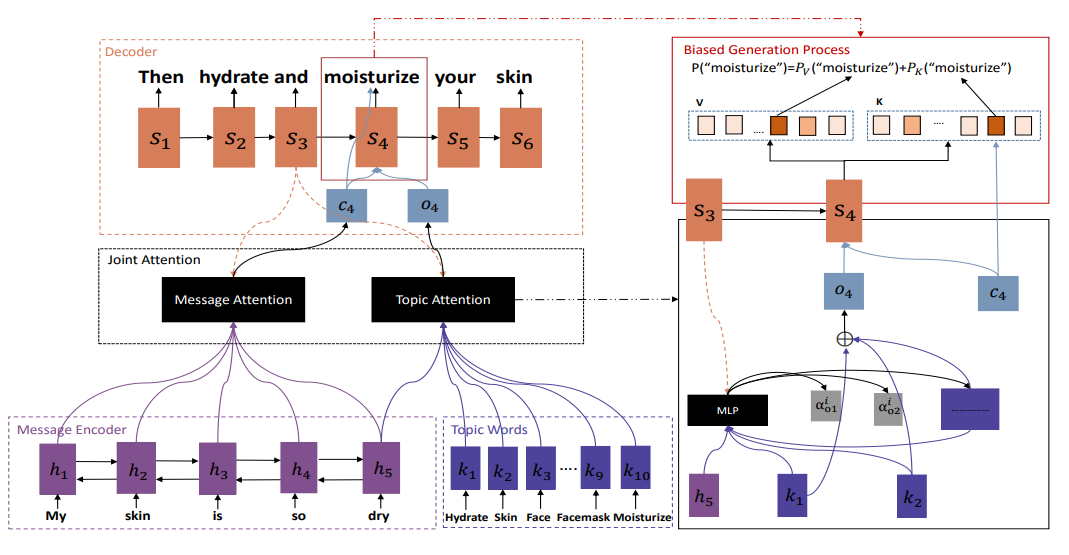
尤其注意的是,在编码的时候,编码器使用双向RNN其问题\(X\)表示成向量\(\lbrace h_t\rbrace_{t=1}^T\),同时,主题编码器从主题词列表中根据主题词分布公式选取\(X\)的主题\(K\)(n个)对应的编码.记为\((k_1,…,k_n)\).
解码过程中,在step \(i\)的时候,除了对问题做attention(message attention)之外,还对主题词做attention(Topic attention),主题词的embedding记为\(\lbrace k_j\rbrace_{j=1}^n\),那么代表主题的向量\(o_i\)则可以由各主题词加权得到,对于\(k_j\)的权重可以由下公式计算得到:
$$a_{ij}^i=\frac{exp(\eta_o(s_{i-1},k_j,h_T))}{\sum_{j’=1}^nexp(\eta_o(s_{i-1},k_{j’},h_T))}$$
其中\(s_{i-1}\)是解码器第\({i-1}\)个的hidden state,\(h_T\)是编码器最后一个hidden state,\(\eta_o\)是一个多层感知机.对比传统的attention,Topic attention使用encoder中最后一个hidden state,可以削弱与问题无关主题的影响和突出相关主题的重要性.
定义词的生成概率\(p(y_i)=p_V(y_i)+p_K(y_i)\),其中\(p_V(y_i)\)和\(p_K(y_i)\)定义为:
$$p_V(y_i=w)=\begin{cases}
\frac{1}{Z}e^{\psi_V(s_i,y_{i-1},w)},&w\in V\cup K\\\
0,&w\notin V\cup K
\end{cases}$$
$$p_K(y_i=w)=\begin{cases}
\frac{1}{Z}e^{\psi_V(s_i,y_{i-1},c_i,w)},&w\in K\\
0,&w\notin K
\end{cases}$$ $$s_i=f(y_{i-1},s_{i-1},c_i,o_i)$$
其中\(V\)回答的词典,\(f\)是一个GRU unit,\(\psi_V(s_i,y_{i-1})\)和\(\psi_K(s_i,y_{i-1},c_i)\)定义为
$$\psi_V(s_i,y_{i-1},w)=\sigma(\mathbf {w^T(W_V^ss_i+W_V^yy_{i-1}+b_V))},\\
\psi_K(s_i,y_{i-1},c_i,w)=\sigma(\mathbf {w^T(W_K^ss_i+W_K^yy_{i-1}+W_Kc+b_K))}$$
其中\(\sigma()\)是tanh函数,\(\mathbf w\)是词\(w\)的ont-hot向量,\(Z\)是一个标准化器.
概率\(p_V(y_i)\)类似于seq2seq加上attenion机制,对于\(p_K(y_i)\),相当于一个使得回答生成句子生成概率产生偏差的额外的概率项.
这个模型的另外一个有点是在生成回答的第一个词的时候,不仅考虑了问题的信息,还包含了主题信息,这样第一个词生成的好了,根据句子生成的原理,就可以提高后面生成的质量.
模型评估
文章对模型进行了三个指标的评估
评价标准
1 Perplexity
$$PPL=exp\lbrace -\frac{1}{N}\sum_{i-1}^N log(p(\mathbf {Y_i}))$$
2 Distinct-1 & distinct-2
计算生成句子的unigrams和bigrams的不同的个数和和占所有unigrams与bigrams的比例,用这个指标来衡量生成句子的信息量,越大表示出现的多样性越好.
3 Human annotation
人工评价
1. +2:回复不仅自然流畅,还有内涵和有趣
2. +1:回复可以用于回到问题,但是太普遍,比如"我不知道"
3. 0:回复对不上问题
结果
在人工评估中,TA-Seq2Seq模型生成的有趣回答有44.7,比以前的方法提高了百分之10几.生成效果得到了很好的提升.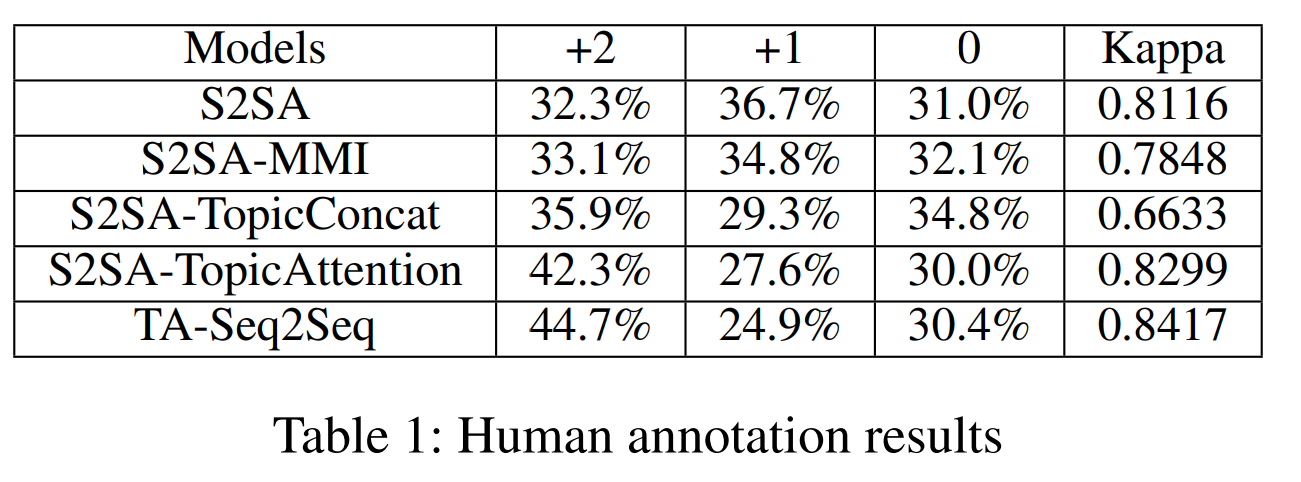
模型的PPl指标比当时最优的QA模型都好,湘江了挺多,而且从distince指标可以看出,富含的信息也原多于之前的模型.
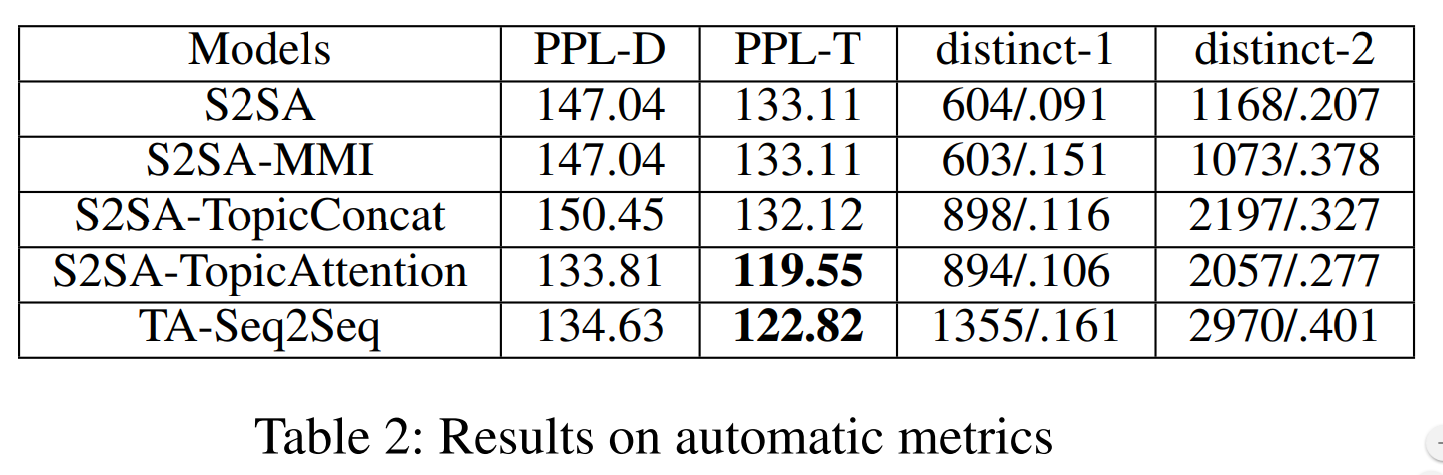
模型对比了S2SA-MMI和S2SA生成的句子,可以看出,明显给力很多.

链接
论文 Topic Aware Neural Response Generation
数据集,论文使用的数据并没有公开,是爬百度和新浪得到了,所以木有数据.
注释
所有数据,图表均来源于论文.