摘要
论文在原seq2seq+attention的基础上引入了copy机制,称为COPYNET机制.这个东西参考了人类交流中对于特别的词直接搬过来用的思想,比如一些专有名词,不懂的词之类的词.在文本摘要任务中的表现甩开了以前的方法.
COPYNET
对于seq2seq+attention不再展开讨论.直接进入主题.复制机制在建模的时候一般比较难处理,文中提出一了中可以完全微分的带有复制机制的seq2seq模型,因此可以通过梯度下降来进行端对端的学习.
1 模型概述
如下图所示,COPYNET仍然是一个encoder-decoder的框架.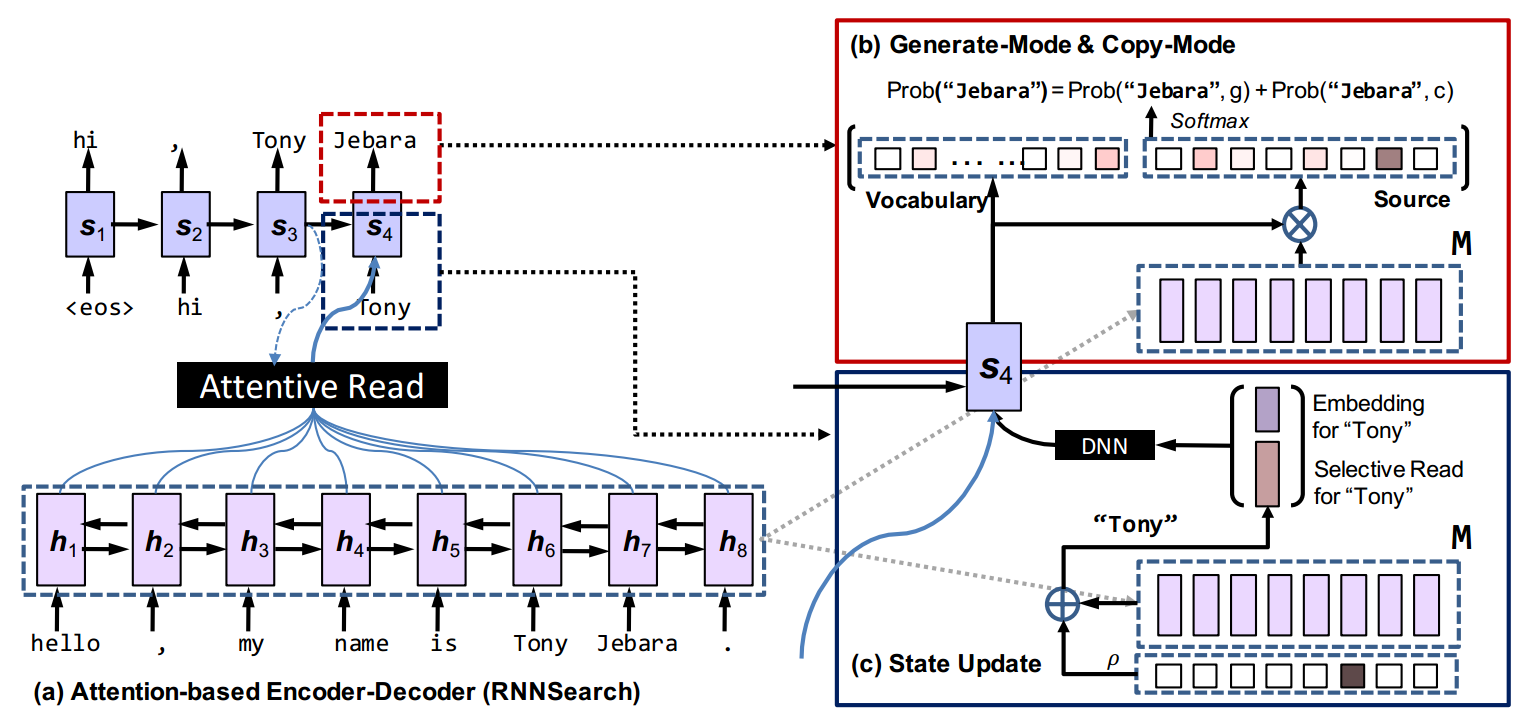
Encoder: 与之前的Encoder一样都是采用双向RNN来将句子转换成一组等长的hidden state.将每个词\(x_t\),表示成\(\lbrace h_1,…,h_T\rbrace\),记为\(\mathbf M\),最后通过几个方法来将其Decoding.
Decoder: 用一个RNN通过读取\(\mathbf M\)来生成目标句子,与以前的RNN-decoder类似,只是一下几点不同:
- Prediction: COPYNET根据两个模型的混合概率来生成词,一个是生成模型,一个是负责从源句子中选词的复制模型.
- State Update: 以前在\(t-1\)时刻预测出来的词用来更新第\(t\)个时刻的状态,但是COPYNET不仅仅用这个词的embedding,还拼接上了这个词在\(\mathbf M\)中特定位置的状态.
- Reading M: COPYNET会选择性的读取\(\mathbf M\)来获取混合了内容寻址和位置寻址的信息.
2 复制和生成预测
假设词典为\(\nu =\lbrace v_1,…,v_N\rbrace\),词典以外的词为UNK.另外对于句子的词组成的的集合有\(\chi =\lbrace x_1,…,x_{T_S}\rbrace \).
给定decoder第\(t\)时刻的状态\(s_t\),\(\mathbf M\),可以生成所有词的混合概率\(y_t\):
$$p(y_t|\mathbf {s_t},y_{t-1},\mathbf {c_t},\mathbf M)=p(y_t,\mathbf g|\mathbf {s_t},y_{t-1},\mathbf {c_t},\mathbf M)+p(y_t, \mathbf c|\mathbf {s_t},y_{t-1},\mathbf {c_t},\mathbf M)$$
这里\(g\)代表生成模型,\(c\)代表复制模型,两种模型的概率计算为:
$$p(y_t,\mathbf g|\cdot)=
\begin{cases}
\frac{1}{Z}e^{\psi_g(y_t)}, &y_t \in \nu \\
0, &y_t \in \chi \cap \overline{\nu} \\\frac{1}{Z}e^{\psi_g(UNK)} &y_t \notin \nu \cup \chi
\end{cases} $$
$$p(y_t,\mathbf c|\cdot)=
\begin{cases}
\frac{1}{Z}\sum_{j:x_j=y_t}e^{\psi_c(x_j)}, &y_t \in \chi \\
0 &otherwise
\end{cases}
$$
在这里\(\psi_h(\cdot)\)和\(\psi_c(\cdot)\)分别是生成模型和复制模型的得分函数,\(Z\)是标准化项.\(Z=\sum_{v\in \nu \cup \lbrace UNK\rbrace}e^{\psi_g(v)}+\sum_{x\in \chi}e^{\psi_c(x)}\),因为要共享标准化项,所以两个模型要首先经过一个\(softmax\),用下图来表示4种decoder概率\(p(y_t|\cdot)\).
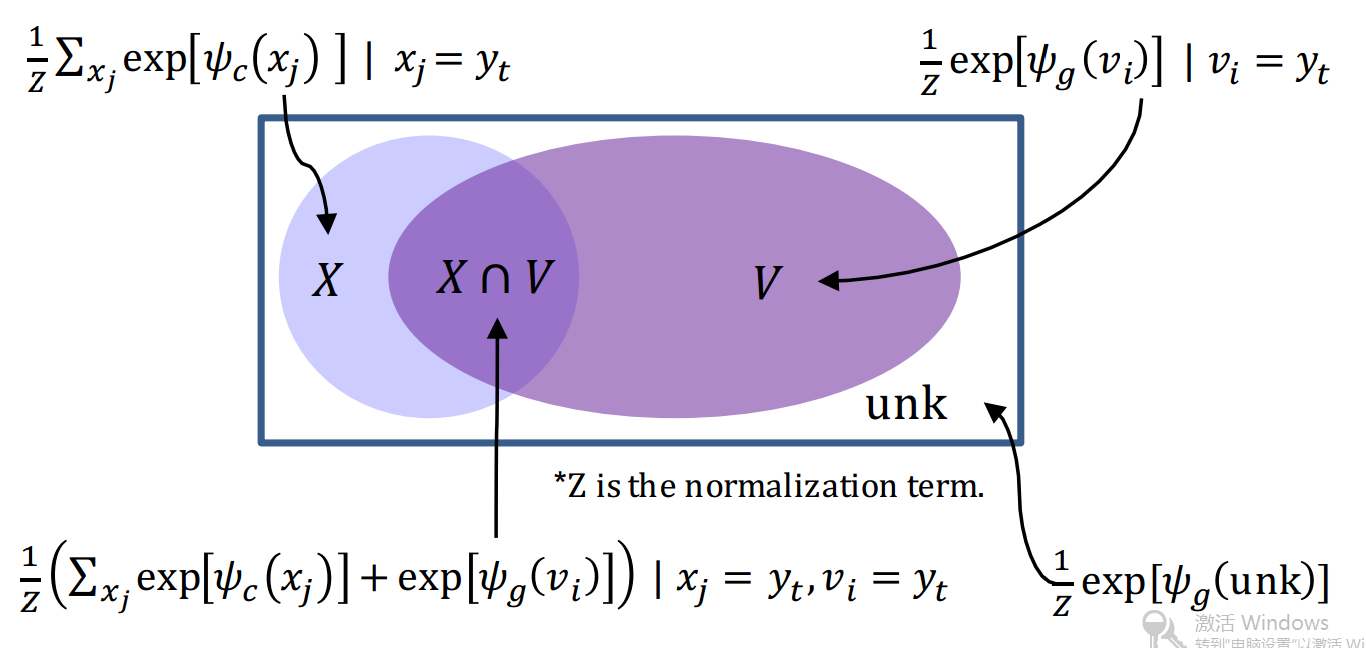
生成模型:使用一样的跟通用Rnn encoder-decoder一样的计算方法:
$$\psi(y_t=v_i)=v_i^TW_os_t,\qquad v_i\in \nu \cup UNK$$
其中\(W_o\in R^{(N+1)*d_s}\),\(v_i\)是词\(v_i\)的one-hot向量.
复制模型:计算词\(x_j\)的复制得分方法:
$$\psi(y_t=x_j)=\sigma(v_j^TW_c)s_t,\qquad x_j\in \chi$$
这里\(W_c\in R^{d_h*d_s}\),\(\sigma(\cdot)\)是一个非线性变换,文中说发现使用tanh比线性变换要好,所以文中的实验是用的tanh.计算复制模型时候,用双向RNN来将文本信息和位置信息表示成hidden states(\(\mathbf M\)).值得注意的是,将所有的\(x_j\)的概率加起来用\(y_t\)表示,是因为可能有多个这样的词在源句子中.
另外,如果\(y_t\)没有出现在源句子中,那么有\(p(y_t,\mathbf c|\cdot)=0\);如果\(y_t\)只出现在源句子中,不在词典里面,那么有\(p(y_t,\mathbf g|\cdot)=0\).
3 状态更新
COPYNET更新状态的方法与通用的attention-based seq2seq模型不一样.在\(y_{t-1}\longrightarrow s_t\)的时候,\(y_{t-1}\)表示为\([e(y_{t-1};\varsigma (y_{t-1})]^T\),其中\(e(y_{t-1})\)是词向量表示,\(\varsigma (y_{t-1})\)是\(M\)中的hidden state对应\(y_t\)的加权和.
$$\varsigma(y_{t-1})=\sum_{\tau=1}^{T_s}p_{t\tau}\mathbf {h_\tau}$$ $$p_{t\tau}=
\begin{cases}
\frac{1}{K}p(x_\tau,\mathbf c|s_{t-1},\mathbf M), & x_\tau=y_{t-1} \\
0 & otherwise
\end{cases}
$$
这里\(K\)是一个标准化项,等于\(\sum_{\tau’:x_{\tau’}=y_{t-1}}p(x_{\tau’},\mathbf c|s_{t-1},M)\),表示词\(y_{t-1}\)可能在源句子中有多个位置.
从某种意义来讲\(\varsigma(y_{t-1})\)相当于是一种在\(M\)上的注意力读取具有很高的精度,文章成为选择性读取,它在复制模型中被专门设计为:对应与\(y_{t-1}\)的精确位置,自然以hidden state的形式编码了\(y_{t-1}\)的位置.这种设计有助于复制连续的子序列.如果\(y_{t-1}\)不在源句子中,那么让\(\varsigma(y_{t-1})=0\)
按照鄙人的理解,就是有三种情况
\(y_{t-1}\)不在源句子中,那么\(\varsigma(y_{t-1})\)为0.
\(y_{t-1}\)在源句子中只出现一次,那么\(\varsigma(y_{t-1})\)为对应的出现位置的hidden state.
\(y_{t-1}\)在源句子中出现多次,那么\(\varsigma(y_{t-1})\)为按照公式算出那些出现位置的hidden state的加权和.
4 \(\mathbf M\)的混合寻址
给予位置的寻址:根据\(h_i\)的位置细信息,信息流动过程为:
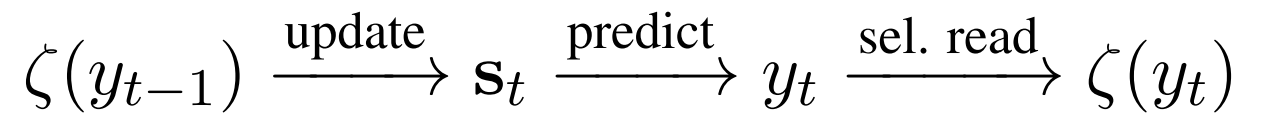
这是一个向右移一步的简单例子.当\(\varsigma(y_{t-1})\)定位在\(X\)中的地\(l^{th}\)个词的时候,状态更新\(\varsigma(y_{t-1}) \;{update}\; s_t\)使得\(s_t\)在预测的时候更偏向与\(X\)中的第\(l^{th}\)个词,然后就形成了复制机制.
OOV词处理 虽然不能确切证明,但是真的有用.
目标函数
因为COPYNET可以完全微分,那么可以通过端对端的训练方法来训练,目标是最小化负的对数似然估计:
$$L=-\frac{1}{N}\sum_{k=1}^N\sum_{t=1}^Tlog[p(y_t^{(k)}|y_{\lt t}^{(k)},X^{(k)})]$$
实验
实验在三个不同特点的数据进行
- 合成数据
- 摘要生成数据
- 单轮对话数据
本文对最后两个就行讨论.
1 摘要生成
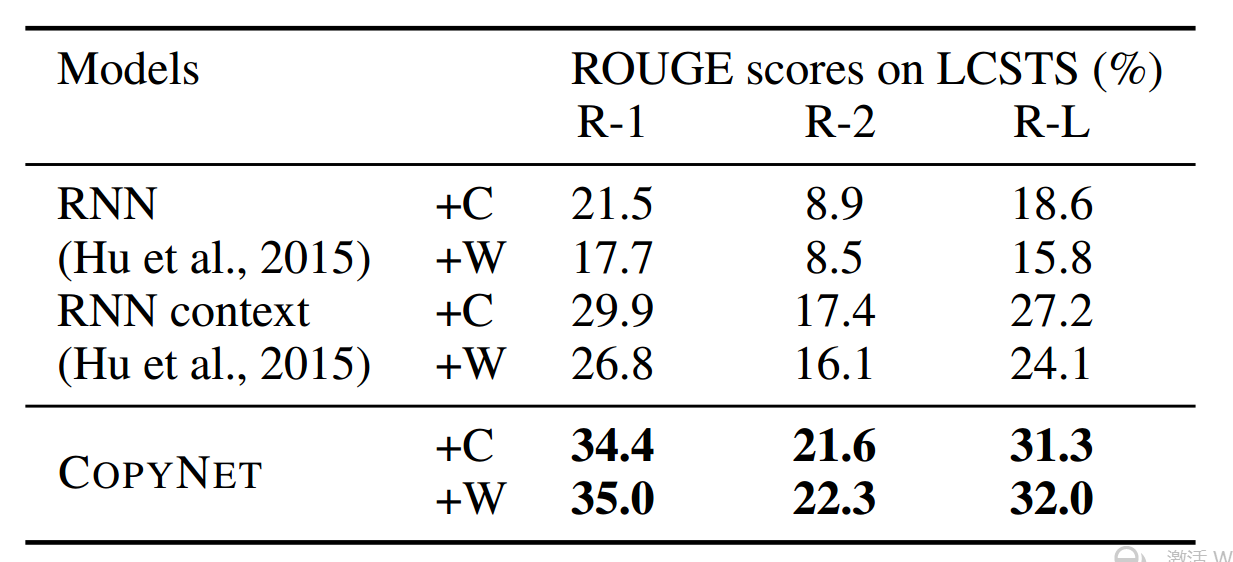
数据集 数据使用的是LCSTS 数据集合,一个从新浪微博爬去的新闻摘要数据.文中只使用里面评分3到5分的数据,第一部分作为训练集合,第三部分作为测试集.
实验设置 分别用字 (+C) 和词 (+W) 来训练模型,使用字的时候,字典大小为3000,用词的时候,词典大小为10000.评估指标使用ROUGE-1,ROUGE-2和ROUGE-L (Lin,2004).
从如中可以看出,COPYNET狠狠的打败了其他模型.
而且从下图也可以看出,产生的摘要质量也是蛮好的.

> 更多结果查看论文
2 单轮对话
数据集 数据从三个渠道得到
1. 从百度贴吧中获取
2. 通过插槽模式获得,如Q:你好,我叫x. A:你好,x.这些对应的是一个输入多种输出的.
3. 与合成数据类似,通过天从序列槽来生成数据,比如带有人命,时间的数据.
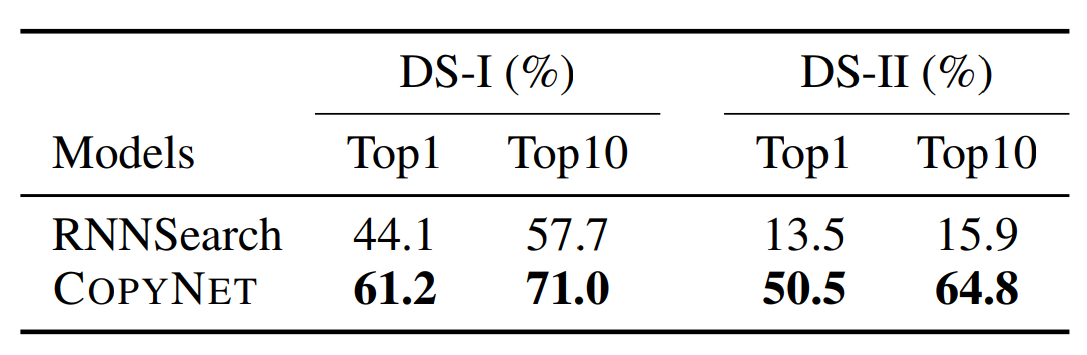
实验设置 实验通过173个模板构建了两个数据集合DS-1和DS-2,主演的区别是DS-2中的训练集和测试集没有重叠.每个数据集合用6500个作为训练集合,1500个作为测试集合.
实验评价指标是同Beam search出来1个或者10个句子和golden的匹配程度.实验表明优于RNNsearch,尤其是在DS-2中,差异更大.
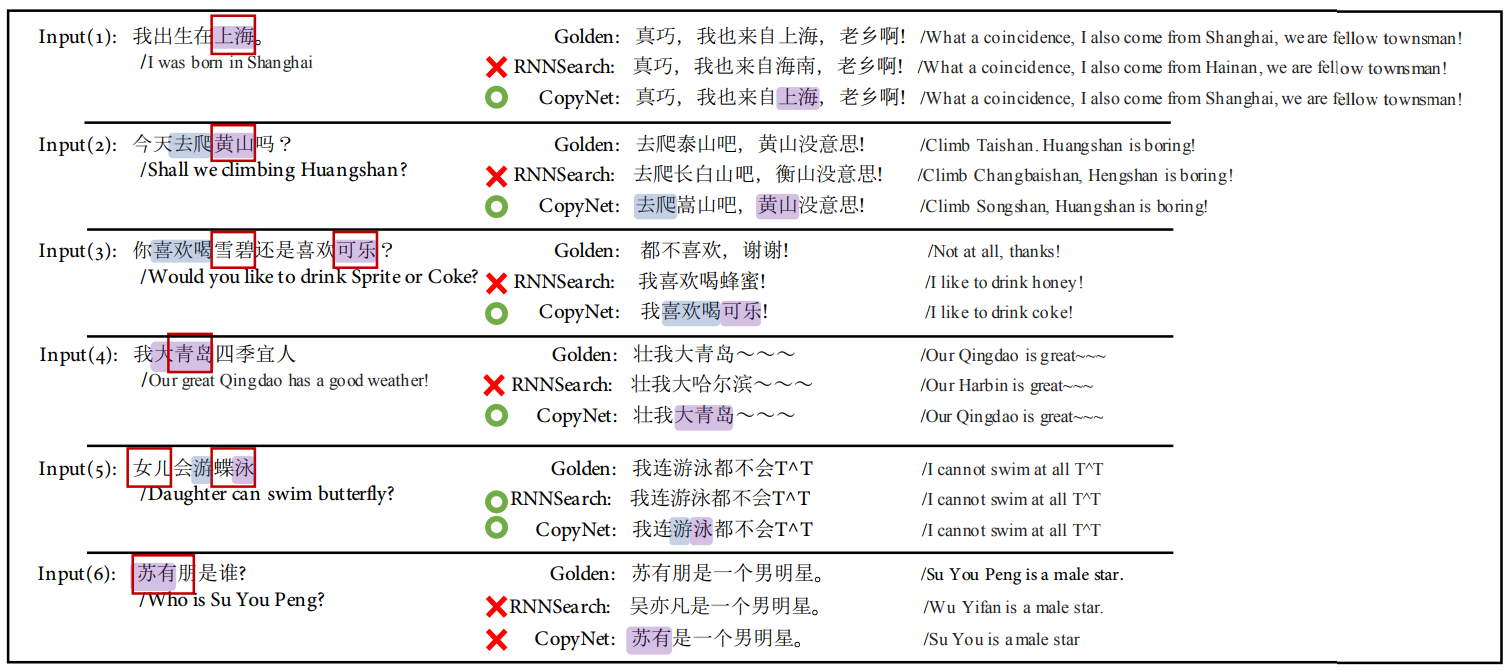
而且生成的句子好像也比较合理.
总结
论文提出了一种可以微分的复制机制,在涉及到要复制词的任务中表现得很好.毕竟在很多NLP任务中,复制的操作还是很重要.
链接
论文 Incorporating Copying Mechanism in Sequence-to-Sequence Learning
数据集,论文使用的数据并没有公开,是爬百度和新浪得到了,所以木有数据.
注释
所有数据,图表均来源于论文.